
Hello friends if you are looking for SAP HANA Interview Questions then here you will get the SAP HANA Multiple Choice questions | SAP HANA interview Questions with answers | Sap HANA interview questions for experienced | SAP HANA real time Interview Questions | Deloitte SAP HANA technical Interview Questions then here you will get answers for it
What is SAP HANA?
Answer : SAP HANA is an in-memory database.
Ø It is a combination of hardware and software made to process massive real time data
using In-Memory computing.
Ø It combines row-based, column-based database technology.
Ø Data now resides in main-memory (RAM) and no longer on a hard disk.
Ø It’s best suited for performing real-time analytics, and developing and deploying
real-time applications.
An in-memory database means all the data is stored in the memory (RAM). This is no
time wasted in loading the data from hard-disk to RAM or while processing keeping
some data in RAM and temporary some data on disk. Everything is in-memory all the
time, which gives the CPUs quick access to data for processing.
SAP HANA is equipped with multi engine query processing environment which
supports relational as well as graphical and text data within same system. It provides
features that support significant processing speed, handle huge data sizes and text
mining capabilities.
what is the role of the persistence layer in SAP HANA?
SAP HANA has an in-memory computing engine and access the data
straightaway without any backup. To avoid the risk of losing data in case of hardware
failure or power cut-off, persistence layer comes as a savior and stores all the data in the
hard drive which is not volatile.
What are the components or products of HANA?
Ø SAP HANA contains the following components.
Ø SAP HANA DATABASE
Ø SAP HANA Studio SAP HANA CLIENT
Ø SAP HANA INFORMATION COMPOSE
Ø DIAGNOSTIC AGENT 7.3
Ø SAP HANA client package for MS excel
Ø SAP HANA UI for Information Access (INA)
Ø SAP HANA AFL 1.0
Ø Software Update Manager for SAP HANA
Ø SAP LT Replication Add On
Ø SAP LT Replication Server
Ø SAP HANA Direct Extractor Connection (DXC)
Ø SAP Data Services 4.0
What are the different editions available in HANA appliance software?
Ø Platform Edition:
Platform edition is intended for customers who want to use ETL-based
replication and already have a license for SAP BO Data Services.
Ø Enterprise Edition:
Enterprise edition is intended for customers who want to use either
trigger-based replication or ETL-based replication and do not already
have all of the necessary licenses for SAP BO Data Services.
What is SAP In-Memory Appliance (SAP HANA)?
HANA is an in-memory technique to store data that is particularly suited for handling very large amounts of tabular, or relational, data with extra ordinary performance. Common databases store tabular data row-wise. Reorganizing the data in memory column-wise brings a tremendous speed
increase when accessing a subset of the data in each table row.
What is columnar and Row-Based Data Storage?
database table contains data in the form of rows and columns. However Computer memory is organized as a linear structure. To store a table in linear memory, there are two options. A row-based storage stores a table as a sequence of records, each of which contains the fields of one row. In a columnar storage the entries of a column are stored in contiguous memory locations. The SAP HANA database allows specifying whether a table is to be stored column-wise or row-wise. It is also possible to alter an existing table from columnar to row-based and vice versa. Search operations in tabular data can be accelerated by organizing data in columns instead in
rows.
Why SAP HANA is fast?
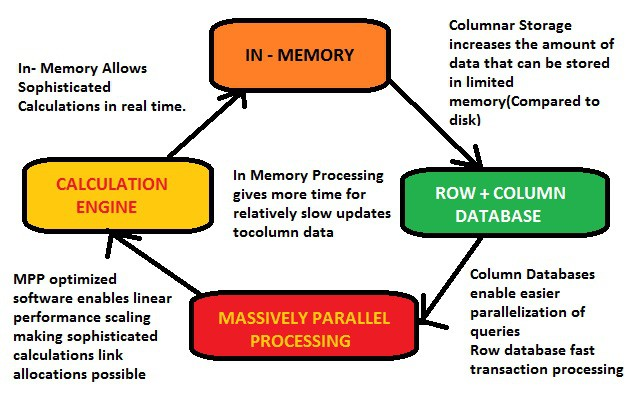
What is paralisation?
Column-based storage makes it easy to execute operations in parallel using multiple processor cores. In a column store data is already vertically partitioned means that operations on different columns can easily be processed in parallel. If multiple columns need to be searched or aggregated, each of these operations can be assigned to a different processor core. In addition operations on one column can be parallelized by partitioning the column into multiple sections that can be processed by different processor cores
What are the different Compression Techniques?
- Run-length encoding
- Cluster encoding
- Dictionary encoding
Why materialized aggregates are not required?
With a scanning speed of several gigabytes per millisecond, in-memory column stores, make it possible to calculate aggregates on large amounts of data on the fly with high performance. This is expected to eliminate the need for materialized aggregates in many cases.
What are the advantages of Eliminating materialized aggregates?
Ø Simplified data model
Ø Simplified application logic
Ø Higher level of concurrency and With the fly Aggregation we have aggregated
values up to date
What are the different types of replication techniques?
Ø ETL based replication using BODS
Ø Trigger based replication using SLT
Ø Extractor based data acquisition using DXC
Define Five-minute rule?
It is a rule of thumb for deciding whether a data item should be kept in memory on stored on disk and read back into memory when required. The rule is “randomly accessed disk pages of cache are re-used every 5 minutes”.
Define multi-core CPU?
Multiple CPU’s on one chip or in one package is called multi-core CPU.
Define Stall?
Waiting for data to be loaded from main memory into the CPU cache is called as Stall.
What are the advantages of Column based tables?
Calculations are typically executed on single or a few columns only.
Ø The table is searched based on values of a few columns.
Ø The table has a large number of columns.
Ø The table has a large number of rows and columnar operations are required
(aggregate, scan, etc.).
Ø High compression rates can be achieved because the majority of the columns
contain only few distinct values (compared to number of rows).
What are the advantages of Row-based tables?
Ø The application needs to only process a single record at one time (many
selects and/or updates of single records).
Ø The application typically needs to access a complete record (or row).
Ø The columns contain mainly distinct values so that the compression rate
would be low.
Ø Neither aggregations nor fast searching are required.
Ø The table has a small number of rows (e. g. configuration tables).
What source databases does HANA support in real-time?
If you use Sybase Replication Server (SRS) for near real-time data then you need to watch out for licensing still (SAP have license deals pending). If you run DB2 then you’re fine but with Oracle and Microsoft SQL Server there are some license challenges if you buy your license through SAP, because you may have a limited license that does not allow extraction. Talk to SAP for further information on this.
What source databases does HANA support for batch loads?
If you use SAP BusinessObjects Data Services 4.0 for bulk loads then pretty much anything. BO-DS is a very flexible Extract, Transform & Load tool that supports many databases – check out the specs for more details.
What additional limitations does Sybase Replication Server present?
SRS has additional restrictions which are worth bearing on mind. It can only replicate Unicode data and does not support IBM DB2 compressed tables.
Follow-ons, corrections & credits
This is a work in progress and your help correcting me, clarifying some things I may have not explained so well or even just asking a question that I haven’t covered would be really useful for the wider market. Let me know and I’ll expand this as the months go on!
Define SLT?
SLT stands for SAP Landscape Transformation which is a trigger based replication. SLT replication server is the replication technology to pass data from source system to the target system. The source can be either SAP or non-SAP. Target system is SAP HANA system which contains HANA database.
What is Configuration in SLT?
The information to create the connection between the source system, SLT system, and the SAP HANA system is specified within the SLT system as a Configuration. You can define a new configuration in Configuration & Monitoring Dashboard (transaction LTR).
What is Configuration and Monitoring Dashboard?
It is an application that runs on SLT replication server to specify configuration
information (such as source system, target system, and relevant connections) so that data
can be replicated. It can also use it to monitor the replication status (transaction LTR).
Ø Status Yellow: It may occur due to triggers which are not yet created successfully.
Ø Status Red: It may occur if master job is aborted (manually in transaction SM37).
What is advanced replication settings
A transaction that runs on SLT replication server to specify advanced replication
settings like
a. Modifying target table structures,
b. Specifying performance optimization settings
c. Define transformation rules
Define Latency?
It is the length of time to replicate data (a table entry) from the source system to the target system.
What are the different types of replication techniques?
1.ETL based replication using BODS
2.Trigger based replication using SLT
3.Extractor based data acquisition using DXC
What is SLT?
SLT stands for SAP Landscape Transformation which is a trigger based replication. SLT replication server is the replication technology to pass data from source system to the target system. The source can be either SAP or non-SAP. Target system is SAP HANA system which contains HANA database.
Is it possible to load and replicate data from one source system to multiple target database schemas of HANA system?
Yes. It is possible for up to 4.
Is it possible to specify the type of data load and replication?
Yes either in real time, or scheduled by time or by interval.
What is Configuration in SLT?
The information to create the connection between the source system, SLT system, and the SAP HANA system is specified within the SLT system as a Configuration. You can define a new configuration in Configuration & Monitoring Dashboard (transaction LTR).
Is there any pre-requisite before creating the configuration and replication?
For the SAP source systems DMIS add-on is installed in SLT replication server. User for RFC connection has the role IUUC_REPL_REMOTE assigned but not DDIC. For non-SAP source systems DMIS add-on is not required and grant a database user sufficient authorization for data replication.
What is an Analytic view?
Analytic views are used to model data that includes measures. In case of multiple tables,
measures must originate from only one of these tables (central table). You can model
Columns, Calculated columns, Restricted columns, Variables, and Input parameters.
Also you can fine-tune the attributes of an Analytic view:
Can apply filter to restrict values
Can be defined as Hidden so that they can be processed but not visible to end users
Can be defined as key attributes and used when joining multiple tables
Can be further drill down by ‘Drill Down Enable’ property
You can model Aggregation type on measures
You can model Currency and Unit of Measure.
Can we include Attribute views in Analytic view definition?
Yes
What does the Scenario panel of Analytic view editor contains?
Data Foundation: represents the tables used for defining the fact table of the view. You
can specify the central table by selecting a value in ‘Central Entity’ property.
Logical Join: represents the relation between fact table and attribute views to create start
schema.
Semantics: represents the output structure of the view.
When to change the number of Data Transfer jobs ?
If the speed of the initial load/replication latency time is not satisfactory If SLT replication server has more resources than initially available, we can increase the number of data transfer and/or initial load jobs After the completion of the initial load, we may want to reduce the number of initial load jobs
What are the jobs involved in replication process ?
- Master Job (IUUC_MONITOR_)
- Master Controlling Job (IUUC_REPLIC_CNTR_)
- Data Load Job (DTL_MT_DATA_LOAD_<2digits>) 4.Migration Object Definition Job (IUUC_DEF_MIG_OBJ<2digits>)
5.Access Plan Calculation Job (ACC_PLAN_CALC__<2digits>)
What is the relation between the number of data transfer jobs in the configuration settings and the available BGD work processes ?
Each job occupies 1 BGD work processes in SLT replication server. For each configuration, the parameter Data Transfer Jobs restricts the maximum number of data load job for each mass transfer ID (MT_ID).
A mass transfer ID requires at least 4 background jobs to be available:
One master job
One master controller job
At least one data load job
One additional job either for migration/access plan calculation/to change configuration
settings in “Configuration and Monitoring Dashboard”.
If you set the parameter “data transfer jobs” to 04 in a configuration “SCHEMA1”, a mass transfer ID 001 is assigned. Then what jobs should be in the system ?
1 Master job (IUUC_MONITOR_SCHEMA1)
1 Master Controller job (IUUC_REPL_CNTR_001_0001)
At most 4 parallel jobs for MT_ID 001 (DTL_MT_DATA_LOAD_001_
01/~02/~03/~04)
Performance: If lots of tables are selected for load / replication at the same time, it may
happen that there are not enough background jobs available to start the load procedure
for all tables immediately. In this case you can increase the number of initial load jobs,
otherwise tables will be handled sequentially.
For tables with large volume of data, you can use the transaction “Advanced Replication
Settings (IUUC_REPL_CONT)” to further optimize the load and replication procedure
for dedicated tables.
So is SAP making/selling the software or the hardware?
SAP has partnered with leading hardware vendors (HP, Fujitsu, IBM, Dell etc) to sell
SAP certified hardware for HANA.
SAP is selling licenses and related services for the SAP HANA product which includes
the SAP HANA database, SAP HANA Studio and other software to load data in the
database.
What is the language SAP HANA is developed in?
The SAP HANA database is developed in C++.
What is the operating system supported by HANA?
Currently SUSE Linux Enterprise Server x86-64 (SLES) 11 SP1 is the Operating System supported by SAP HANA.
Can I just increase the memory of my traditional Oracle database to 2TB and get similar performance?
NO.
You might have performance gains due to more memory available for your current Oracle/Microsoft/Teradata database but HANA is not just a database with bigger RAM. It is a combination of a lot of hardware and software technologies. The way data is stored and processed by the In-Memory Computing Engine (IMCE) is the true differentiator. Having that data available in RAM is just the icing on the cake.
How does SAP HANA support Massively Parallel Processing?
With availability of Multi-Core CPUs, higher CPU execution speeds can be achieved.
Also HANA Column-based storage makes it easy to execute operations in parallel using
multiple processor cores. In a column store data is already vertically partitioned. This means that operations on different columns can easily be processed in parallel. If multiple columns need to be
searched or aggregated, each of these operations can be assigned to a different processor
core.
In addition operations on one column can be parallelized by partitioning the column into
multiple sections that can be processed by different processor cores. With the SAP
HANA database, queries can be executed rapidly and in parallel.
two types of Relational Data stored in HANA?
The two types of relational data stored in HANA includes
· Row Store
· Column Store
what is the role of the persistence layer in SAP HANA?
SAP HANA has an in-memory computing engine and access the data straightaway without any backup. To avoid the risk of losing data in case of hardware failure or power cutoff, persistence layer comes as a savior and stores all the data in the hard drive which is not volatile.
what is modeling studio?
Modeling studio in HANA performs multiple task like
· Declares which tables are stored in HANA, first part is to get the meta-data and then schedule data replication jobs
· Manage Data Services to enter the data from SAP Business Warehouse and other systems
· Manage ERP instances connection, the current release does not support connecting to several ERP instances
· Use data services for the modeling
· Do modeling in HANA itself
· essential licenses for SAP BO data services
what are the different compression techniques?
There are three different compression techniques
· Run-length encoding
· Cluster encoding
· Dictionary encoding
Mention what is latency?
Latency is referred to the length of time to replicate data from the source system to the
target system.
Explain what is transformation rules?
Transformation rule is the rule specified in the advanced replication setting transaction for the source table such that data is transformed during the replication process.
what is the advantage of SLT replication?
· SAP SLT works on trigger based approach; such approach has no measurable
performance impact in the source system
· It offers filtering capability and transformation
· It enables real-time data replication, replicating only related data into HANA
from non-SAP and SAP source systems
· It is fully integrated with HANA studios
· Replication from several source systems to one HANA system is allowed, also
from one source system to multiple HANA systems is allowed.
Explain how you can avoid un-necessary information from being stored?
To avoid un-necessary information from being stored, you have to pause the replication by stopping the schema-related jobs
what is the role of master controller job in SAP HANA?
The job is arranged on demand and is responsible for
· Creating database triggers and logging table into the source system
· Creating Synonyms
· Writing new entries in admin tables in SLT server when a table is
replicated/loaded
Explain what happens if the replication is suspended for a longer period of time
or system outage of SLT or HANA system?
If the replication is suspended for a longer period of time, the size of the logging tables increases.
What are the different types of replication techniques?
here are 3 types of replication techniques:
- SAP Landscape Transformation (SLT)
- SAP Business Objects Data Services (BODS)
- SAP HANA Direct Extractor Connection (DXC) Note: There is one more replication
technique called Sybase replication. It was part of initial offering for HANA replication.
but not positioned supported anymore due to licensing issues and complexity and mostly
because SLT provides the same features.
What is SLT?
The SAP Landscape Transformation (LT) Replication Server is the SAP technology that allows us to load and replicate data in real-time from SAP source systems and non-SAP source systems to an SAP HANA environment. The SAP LT Replication Server uses a trigger-based replication approach to pass data from the source system to the target system.
What is the advantage of SLT replication?
Advantages: 1. SAP LT uses trigger based approach. Trigger-based approach has no measureable performance impact in source system. 2. It provides transformation and filtering capability. 3. It allows real-time (and scheduled) data replication. replicating only relevant data into HANA from SAP and non-SAP source systems. 4. It is fully integrated with HANA Studio. 5. Replication from multiple source systems to one HANA system is allowed. also from one source system to multiple HANA systems.
Is it possible to use a replication for multiple sources and target SAP HANA systems?
Yes. the SAP LT Replication Server supports both 1:N replication and and N:1 replication. • Multiple source system can be connected to one SAP HANA system. o One source system can be connected to multiple SAP HANA systems. Limited to 1:4 only.
You mean I have to buy a HANA only 2.5x smaller than my big Oracle RDBMS?
What about archiving and data ageing? Yes, in some instances you may have to buy a HANA appliance that is only 2.5x smaller than it would be under Oracle. And data ageing isn’t part of the 1.0 release, but SAP is certainly working on it pretty hard. Let’s hope they release something faster than you need to buy a bigger HANA appliance!
What’s the wider market opportunity for IMDB?
This is the interesting thing – no one knows yet, and few analysts seem to have cottoned on that the wider market opportunity might be huge. Think not just SAP applications but any third party that requires ultra-high speed. Think not just an appliance but a development platform. Time will tell.
1 thought on “SAP HANA Interview Questions with Answers”